First of all, my major job is about to use std::vector instead of DynArray in CDynamicArray. But due to my carelessness and irresponsible, the works described in this blog actually shouldn’t take so long to deliver. I do meet some issues during this two weeks and went into some kind of dilemma, but it shouldn’t take 2 weeks anyway.
Stage – 1(try to use std::vector instead of DynArray directly)
std::vector is the first choice as the alternative of DynArray, it’s dynamic, check, it has almost same interface with DynArray, check, and the most beautiful thing is I don’t know to manually manage the memory by using it.(How naive I am :/)
Ok, after I replace all the DynArray with std::vector directly, the compiler complain like:
error: invalid initialization of non-const reference of type ‘bool&’ from an rvalue of type ‘bool’
And do some research, I found this(https://stackoverflow.com/a/7376997) for it. And I quote part of wiki:
The Standard Library defines a specialization of the vector template for bool. The description of this specialization indicates that the implementation should pack the elements so that every bool only uses one bit of memory.
looks like I should find another way.
Stage – 2(maybe std::deque is a better choice?)
So I need a container, it must be dynamic and support random index, so it can return reference to bool. Ok, I guess std::deque is something we want. The “only” difference is we can’t direct access to the underlying array,
auto it = m_array.begin();
return &(*it);
But, as wiking said, the elements in deque are not contiguous in memory and the serialization of this object will be broken as result.
Stage – 3(wait! Maybe const_reference and const_pointer works for vector)
After talk with iglesiasg on irc, I found the std::vector<bool> specialization defines std::vector<bool>::reference as a publicly-accessible nested class. std::vector<bool>::reference proxies the behavior of references to a single bit in std::vector<bool> and it can return reference as usual if it’s not bool element. How sweet! But, however, it proves that it’s impossible to return a plain pointer by vector::const_pointer.
Stage – 4(Oh man, just use template specification)
If we can’t make vector works, why not stop using it? So we got:
template class CDynamicArray : public CSGObject
{}
template class CDynamicArray : public CSGObject
{}
Watch out! The template definition should be in one line, otherwise our class_list.cpp.py doesn’t know how to handle it[see github comment for more][and here]. Alright, do you think it’s good to go now? NO! We still got so many errors:
1 – unit-DynamicObjectArray (SEGFAULT) 8 – unit-SGObject (OTHER_FAULT) 12 – unit-GaussianProcessClassification (SEGFAULT) 73 – unit-LineReaderTest (Failed) 81 – unit-CommUlongStringKernel (SEGFAULT) 222 – unit-LogPlusOne (SEGFAULT) 223 – unit-MultipleProcessors (SEGFAULT) 226 – unit-RescaleFeatures (SEGFAULT) 265 – unit-SerializationAscii (OTHER_FAULT) 266 – unit-SerializationHDF5 (OTHER_FAULT) 267 – unit-SerializationJSON (OTHER_FAULT) 268 – unit-SerializationXML (OTHER_FAULT) 343 – libshogun-evaluation_cross_validation_multiclass_mkl (OTHER_FAULT)
Where is the problem?
First problem is DynamicArray :: shuffle(). I shuffle things inside like
std:: shuffle(m_array.begin(), m_array.end())
and it will shuffle all the element in that vector rather than the elements been used. For example, if we have a vector with size 10 and we only use 5 elements in it. It will look like vector{1,2,3,4,5,0,0,0,0,0}. And then the std::shuffle() will make things like {0,1,2,0,0,3,0,4,0,5}. Actually we don’t want any zero in there.
The second problem is DynamicArray :: find_element(). Again, I use
std::find(m_array.begin(), m_array.end(), e)
inside and again, it failed

For example, if we have a vector with size 10 and we only use 5 elements in it. It maybe looks like vector{1,2,3,4,5,0,0,0,0,0}. I bet you already notice it, it will always return true if we want to figure out if we have zero in that array. To fix it:
inline int32_t find_element(bool e)
{
int32_t index = -1;
int32_t num = get_num_elements();
for (int32_t i = 0; i < num; i++)
{
if (m_array[i] == e)
{
index = i;
break;
}
}
return index;
}
As conclusion:
These errors and bug actually not so hard to find out. But I just too trust STL and haven’t figure out what things I need exactly. After I found a bunch of segment fault, the first thing come cross my mind is “it’s a serious problem, I should ask my mentor”. If I have more patience and output all the variable step by step, things will been fixed very fast and wouldn’t wast too much time of my mentor(sincerely sorry to wiking). And I should write unit test before I start my work, so we can catch the problem at the beginning.














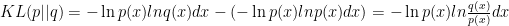 and it’s known as relative entropy or Kullback-Leibler divergence or KL divergence. You could also define it as
and it’s known as relative entropy or Kullback-Leibler divergence or KL divergence. You could also define it as  we could give some conclusion in here: \n
we could give some conclusion in here: \n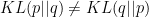
![I[x,y] = \sum_{x \in X, y \in Y} P(x, y)log \frac{P(X,Y)}{P(X)P(Y)}](https://s0.wp.com/latex.php?latex=I%5Bx%2Cy%5D+%3D+%5Csum_%7Bx+%5Cin+X%2C+y+%5Cin+Y%7D+P%28x%2C+y%29log+%5Cfrac%7BP%28X%2CY%29%7D%7BP%28X%29P%28Y%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) or we can just say $I(X; Y) = H(X) – H(X|Y)$
or we can just say $I(X; Y) = H(X) – H(X|Y)$ And you could find that the h(x) is actually represent the “bits”. Now, suppose that a sender wishes to transmit the value of a random variable to a receiver. The average amount of information that they transmit in the process is obtained by taking the expectation of h(x) with respect to the distribution p(x) and is given by
And you could find that the h(x) is actually represent the “bits”. Now, suppose that a sender wishes to transmit the value of a random variable to a receiver. The average amount of information that they transmit in the process is obtained by taking the expectation of h(x) with respect to the distribution p(x) and is given by ![H[x] = - sum_{x}p(x)log_{2}p(x)](https://s0.wp.com/latex.php?latex=H%5Bx%5D+%3D+-+sum_%7Bx%7Dp%28x%29log_%7B2%7Dp%28x%29&bg=ffffff&fg=000000&s=0&c=20201002) . This important quantity is called the entropy of the random variable x. Consider a random variable x having 8 possible states and each of which is equally likely. In order to communicate the value of x to a receiver, we would need to reansmit a message of length 3 bits and the entropy is
. This important quantity is called the entropy of the random variable x. Consider a random variable x having 8 possible states and each of which is equally likely. In order to communicate the value of x to a receiver, we would need to reansmit a message of length 3 bits and the entropy is ![H[x] = -8 * \frac{1}{8}log_{2}\frac{1}{8} = 3 bits](https://s0.wp.com/latex.php?latex=H%5Bx%5D+%3D+-8+%2A+%5Cfrac%7B1%7D%7B8%7Dlog_%7B2%7D%5Cfrac%7B1%7D%7B8%7D+%3D+3+bits&bg=ffffff&fg=000000&s=0&c=20201002) . Furthermore, if we have 8 possible states{a, b, c, d, e, f, g, h} for following strings: 0, 10, 110, 1110, 111100, .
. Furthermore, if we have 8 possible states{a, b, c, d, e, f, g, h} for following strings: 0, 10, 110, 1110, 111100, . , which diverges in the limit
, which diverges in the limit 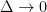 . For a density defined over multiple continuous variables, denoted collectively by the vector x, the different entropy is given by
. For a density defined over multiple continuous variables, denoted collectively by the vector x, the different entropy is given by ![H[x] = - \int p(x)lnp(x)d_{x}](https://s0.wp.com/latex.php?latex=H%5Bx%5D+%3D+-+%5Cint+p%28x%29lnp%28x%29d_%7Bx%7D&bg=ffffff&fg=000000&s=0&c=20201002) which denote the fact that to specify a continuous variable very precisely requires a large number of bits.
which denote the fact that to specify a continuous variable very precisely requires a large number of bits. . Thus the average additional information needed to specify y can be written as
. Thus the average additional information needed to specify y can be written as ![H[y|x] = sum_{x\in \textup{x}, y\in \textup{y}}p(x,y)log \frac{p(x)}{p(x,y)}](https://s0.wp.com/latex.php?latex=H%5By%7Cx%5D+%3D+sum_%7Bx%5Cin+%5Ctextup%7Bx%7D%2C+y%5Cin+%5Ctextup%7By%7D%7Dp%28x%2Cy%29log+%5Cfrac%7Bp%28x%29%7D%7Bp%28x%2Cy%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) which called the conditional entropy of y given x. It’s easily seen, using the product rule, that the conditional entropy satisfies the relation: H[x,y] = H[y|x] + H[x]
which called the conditional entropy of y given x. It’s easily seen, using the product rule, that the conditional entropy satisfies the relation: H[x,y] = H[y|x] + H[x]